

Ask a general AI about your own business and it falls apart. It does not know your pricing, your policies, your product docs, or the conversation you had with a customer last Tuesday. It was trained on the public internet, not on you. RAG is how you fix that without retraining anything.
In short, RAG (retrieval-augmented generation) is a technique that lets an AI look up relevant information from your own documents and use it to answer, instead of relying only on what it memorized during training. You give it a library, and it reads from that library before it speaks.
You have already seen this pattern. Every "chat with this PDF" tool, every support bot that somehow knows a company's exact return policy, every AI that answers from a help center it was clearly fed: that is RAG quietly doing the lookup behind the scenes.

Why does a normal AI not know your stuff?
A language model is, at heart, a very sophisticated pattern of everything it read during training. That training is frozen in time and limited to what was publicly available. Your private notes, your internal wiki, last week's numbers: none of it was in there. So when you ask, the model does the only thing it can, it guesses based on general patterns. RAG replaces that guess with a real lookup.
How does RAG actually work?
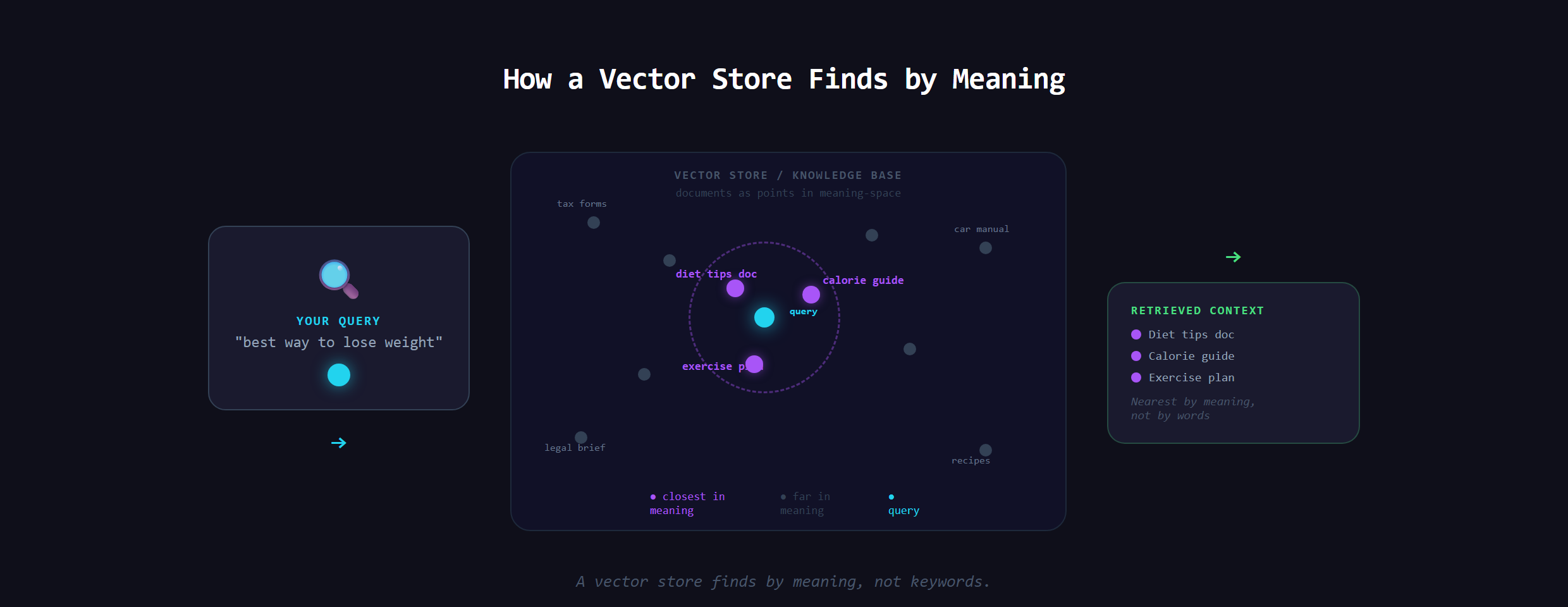
The idea is closer to an open-book exam than to memorizing a textbook. When a question comes in, the system first searches your collection of documents for the passages most relevant to that question. It hands those passages to the AI along with the question, and the AI writes its answer using them. Retrieve the right pages, then generate the answer from them. That two-step shape, look it up first, answer second, is the entire idea.
Why not just paste everything into the prompt?
New builders often ask why you cannot simply give the AI all your documents at once. The problem is volume. An AI can only consider so much text at a time, and a real knowledge base is far too big to fit, far too expensive to send in full, and would bury the relevant part in noise even if it fit. RAG is the smart-search step that finds only the handful of passages that actually matter for this question, so the AI sees the right page instead of the whole library.
Why is RAG better than retraining the model?
You could, in theory, retrain a model on your data so the knowledge lives inside it. In practice that is slow, costly, and stale the moment your data changes. RAG keeps your knowledge in a separate store the AI reads from each time. Change a document and the AI knows the new version instantly, with nothing retrained. That flexibility is why RAG, not retraining, powers most real AI products that need to know specific, changing information.
Where does RAG fit with everything else?
RAG is one of the highest-leverage tools in the modern AI kit, and it pairs naturally with the others. Give an AI agent the ability to retrieve from your knowledge base and it can act on what it finds. Connect that retrieval through an MCP server and it becomes a tool the AI can reach for on demand. RAG is the piece that turns a clever general assistant into one that genuinely knows your world.
What goes wrong without it?
Skip RAG and ask an AI about your own information anyway, and you get the worst outcome in AI: a confident, fluent, completely wrong answer. It will invent a policy, misremember a price, or fabricate a fact, and sound totally sure doing it. Grounding the model in your real documents is the single biggest step toward answers you can actually trust.
Building a RAG system over your own knowledge, the retrieval, the store, and wiring it into the AI, is covered in Venom AI's Tier 4, part of how we teach you to Make Anything With AI. Once an AI can read your library, it stops guessing and starts knowing.